
In this post, we are going to design various artificial intelligence agents to play the classic version of Pacman, including ghosts and capsules. Pacman is a famous Atari game developed back in 1979 by a nine-person team and then released in 1980 by the former Japanese developer and publisher of arcade video games Namco.
The great success the game had at the time, made it survive until the present day becoming one of the greatest and most influential video games of all time. The player, or the agent in our case, controls a yellow character called Mr.Pacman whose objective is to eat all the dots placed in the maze while avoiding the four colored ghosts pursuing him.
Given the popularity of the game, its rules are also well-known and I probably don’t need to explain them here. However, in order to test the agents’ performances, the original game’s rules have been slightly simplified bringing the following changes:
- The ghosts are all controlled by the same kind of AI.
- There is not a fixed number of ghosts.
- Eating a dot rewards 10 points.
- Each step will decrease by 1 point.
- The game ends when all the dots have been cleared or when a ghost eats Mr.Pacman, with no extra lives.
- Eating a capsule will cause the ghosts to be scared, a scared ghost will have its speed halved and will escape from the player rather than pursuing him.
- Eating a scared ghost rewards 200 points.
- Winning the game rewards 500 points.
- Losing the game will subtract 500 points.
- There are different kinds of mazes.
- Some mazes are very challenging 🙂
Now that we have explained our own new rules, let’s watch a useful and interesting video displaying one of the agents we are going to implement playing a match in the original maze. Afterward, we are going to understand their logic and implementation in the following sections.

Agents overview
In the next sections, we are going to develop 5 different agents to control our Mr.Pacman along the mazes. Nevertheless, one of these agents is just a more efficient version of another one, so our 5 agents are going to play accordingly to only 4 different behaviors.
The following list briefly introduces each agent’s strategy leaving their details in the subsequent paragraphs:
- Reflex Agent: an agent that considers food locations, ghost locations, and the score of the current situation to decide its next action.
- Minimax Agent: an adversarial search agent implementing minimax algorithm that keeps into consideration the presence of multiple adversarial agents (ghosts).
- AlphaBeta Pruning Agent: an adversarial search agent implementing minimax algorithm with alpha-beta pruning to more efficiently explore the minimax tree. Basically, alpha-beta pruning is just a faster version of the standard minimax.
- Expectimax Agent: an adversarial search agent implementing expectimax algorithm, it also keeps into consideration the presence of multiple adversarial agents.
- Deep Search Agent: a deep search algorithm that attempts to find the best possible path given an evaluation function. It is faster than minimax but doesn’t keep into consideration ghosts. A similar algorithm has been proposed in this post to make a powerful agent play the game of Snake.
Important: It is worth pointing out that all these agents are based on hard-coded algorithms, thus there is no learning process.
Ghosts AI
In this version of the game have been implemented 2 different policies to control ghosts.
The first one is very simple: ghosts will just wander around the maze randomly, hence, we are going to name them random ghosts. This policy has been designed to be very simple for Pacman agents to win against them, so that even simpler AI agents can have a chance to survive.
Anyway, sometimes also random ghosts can put in trouble the most sophisticated agents, especially when grouped in big clusters or moving in particularly tricky mazes.
The second kind of policy is smarter than the first one and makes ghosts take that action to reduce their distance from Mr.Pacman. Ghosts controlled by this policy are called directional ghosts and represent a much more challenging scenario with respect to the naive random ghosts.
In fact, they are able to pursue Mr.Pacman indefinitely and the only way to get rid of them is to eat a capsule which would cause them to be scared and run away from the player.
Still, these ghosts still show many flaws since they use to act independently without engaging in cooperative tactics and can temporarily get stuck in some particularly tricky paths such as dead ends.
Reflex Agent
The first agent we are going to analyze is the Reflex Agent. It consists of a simple agent that only takes actions based on the current situation of the state of the environment ignoring past and future states. It is based on the simple “condition-action” logic (i.e. ghost on the left and dot on the right -> go right).
More specifically, it uses an evaluation function to compute the goodness of a state and chooses the actions leading to the state with the highest score among the possible ones.
The evaluation function takes into consideration some observations about the environment such as the distance to the closest dot, the distance to the closest ghost, and whether it is scared or not as well as the current score. The value of a state is computed by a linear combination of the above-listed variables that are always known since the agent is acting in a fully observable state, namely, it always knows everything about the environment such as score and element positions.
Despite its simplicity, it behaves pretty well in most mazes, sometimes even competing with more advanced agents, thus representing a good baseline to compare future AIs. The agent is also very fast since it doesn’t require any recursive call, making it suitable also for very big mazes where other agents would be terribly slowed down due to their high computational cost.
Nevertheless, a noticeable flaw is that sometimes Reflex agents can remain stuck in possible loops, thus requiring taking random actions to escape from them.
Important: Video 2 and Video 4 show a Reflex agent playing in two different mazes.
Minimax Agent
The next agent we are going to study is the Minimax Agent. Minimax is a kind of backtracking algorithm that is used in decision-making and game theory to find the optimal move for a player (maximizer), assuming that his opponent (minimizer) also plays optimally.
Similarly to the Reflex agent, each state of the environment has a value associated with it computed through an evaluation function and the maximizer has to try to get the highest value possible while the minimizer has to try to do the opposite and get the lowest value possible.
This algorithm is widely used in two-player turn-based games such as Tic-Tac-Toe, Backgammon, and Chess but we can generalize it to take into account the presence of many adversarial agents (minimizers) and extend it to more complicated games like Pacman.
Minimax under the hood
Now that we have introduced this simple but effective policy, let’s make an example to try to make things more clear. In our game Mr.Pacman is the maximizer and has to choose the best possible move, however, in the beginning, it has no idea where to go, what should it do in this case?
First, he could begin by checking all the actions it can take, that is, going left, right, forward, or backward. Among those directions, it has to discard the directions it can’t go because of the walls of the maze blocking the way. At this point, it would like to know the value of each action it can take in order to choose the optimal one. Hence, it tries to move in each of the remaining directions, thus, changing the state of the environment.
In fact, its actions would cause the movement of itself by one position, could result in one dot being eaten, thus increasing its score, or could result in the player being eaten by a ghost causing game over. If the latter condition would be true, then the current branch terminates returning the value of the evaluation function computed at the reached state (it would be a low value since Mr.Pacman got eaten).
Otherwise, the research continues and this time is the turn of the first ghost, which is one of the minimizers, to move. Similarly to how Mr.Pacman did, also the ghost tries all of its possible moves. Once a ghost has moved, the next ghost takes its action until all ghosts wouldn’t have moved. After the last ghost has moved, a cycle has finished and Mr.Pacman can now take another action.
Afterward, the first ghost moves again, then the second one, and so on until won’t be reached a fixed depth or a ghost wouldn’t have eaten the player. Once a branch of the tree has been fully expanded until its leaf, the algorithm does backtracking returning the value of the state with the maximum value for Mr.Pacman and the value of the state with the minimum value for the ghosts. In this way, the ghosts will have always chosen their best possible moves while the player will have chosen his best moves.
Once the tree has been fully backtracked until the root, the algorithm will return the value of the best possible move Mr.Pacman can take computed with each agent (both player and ghosts) playing according to their best moves.
I can see the future and it allows me to select the best possible move.
Minimax Agent
Minimax is an excellent algorithm since it can return the best possible move in these kinds of games, also known as zero-sum games, where the environment is fully observable and the game is not influenced by external factors such as luck.
Anyway, all that glitters is not gold, despite its tremendous efficacy, minimax algorithm is terribly slow even when involving only two players (a minimizer and a maximizer). Never mind the computational cost required to expand the minimax tree taking into account all the adversarial agents with all their possible moves.
For example, for Mr.Pacman, performing a 3 depth research in a maze with only 2 ghosts would mean simulating at most 43x(2+1) steps (but less considering that some branches might be cut because of Mr.Pacman game over or actions blocked by walls) which would be infeasible to use in big mazes with a lot of ghosts and at the same time useless, even in smaller mazes, if the research depth is not enough.
Here is reported the pseudo-code of the minimax algorithm with multiple adversarial agents searching for the value of the best action.
def minimax(agent, depth, gameState):
# if the game has finished return the value of the state
if gameState.isLose() or gameState.isWin() or depth == max_depth:
return evaluationFunction(gameState)
# if it's the maximizer's turn (the player is the agent 0)
if agent == 0:
# maximize player's reward and pass the next turn to the first ghost (agent 1)
return max(minimax(1, depth, gameState.generateSuccessor(agent, action)) for action in getLegalActionsNoStop(0, gameState))
# if it's the minimizer's turn (the ghosts are the agent 1 to num_agents)
else:
nextAgent = agent + 1 # get the index of the next agent
if num_agents == nextAgent: # if all agents have moved, then the next agent is the player
nextAgent = 0
if nextAgent == 0: # increase depth every time all agents have moved
depth += 1
# minimize ghost's reward and pass the next ghost or the player if all ghosts have already moved
return min(self.minimax(nextAgent, depth, gameState.generateSuccessor(agent, action)) for action in
getLegalActionsNoStop(agent, gameState))
AlphaBeta Agent
The minimax algorithm can have its huge search tree pruned by applying a tweak known as Alpha-Beta pruning which can reduce its computation time by a significant factor.
This tweak allows the search to proceed much faster cutting unnecessary branches which need not be searched because there already exists a better move available. The name alpha-beta pruning is because it requires 2 extra parameters to be passed in the minimax function, namely, alpha and beta:
- Alpha is the best value that the maximizer currently can guarantee at that level or above and is initialized to
-inf. - Beta is the best value that the minimizer currently can guarantee at that level or above and is initialized to
+inf.
The two new parameters are used to prune those branches that cannot possibly influence the final decision. Whenever the maximum score that the minimizing player (beta player) is assured of becoming less than the minimum score that the maximizing player (alpha) is assured of, thus if beta < alpha, the maximizing player doesn’t need to consider further descendants of this node, as they will never be reached in the actual play.
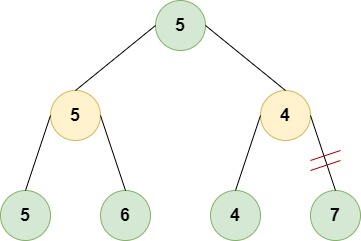
Above is showed a simple example of an alpha-beta pruning minimax variant tree where the nodes at the first and third depth levels are maximizers (green ones) and the two nodes at the second level are minimizers (pink ones).
In a scenario where the tree is explored following the left-first rule, we would find a value equal to min(5, 6)=5 for the left minimizer node, thus alpha=5. Then, during the exploration of the right subtree, we find that the right minimizer node has found a leaf with value 4, thus beta=4.
Now the condition beta < alpha is true so the algorithm doesn’t need to explore the right leaf of the right minimizer which would be 7. This is because the right minimizer would choose the smaller one among its child which is 4 which is less than 5 found by the left minimizer.
Considering that the top maximizer node would choose the bigger among its children, which is the left node with a value of 5, the exploration of the right node of the right minimizer wouldn’t have influenced the final outcome.
If future is not suitable to me, then I will discard it.
AlphaBeta Agent
During evaluation, it will be used the algorithm (AlphaBeta Agent) instead of the standard minimax considering both algorithms yield the same results but in practice, the alpha-beta pruning variant can save up to half of the total time.
Expectimax Agent
The last multi-agent adversarial searching algorithm we are going to explore is the Expectimax Agent. The expectimax algorithm is a variation of the minimax algorithm that takes into account also the uncertainty in the environment.
The maximizers nodes of the tree work as in minimax but the minimizers nodes are replaced by chance nodes whose value is not the value of the minimum of their children but will be computed as the expectation of their children’s value. Note that in order to calculate this expectation there must be a known probability of reaching each child.
However, for most games, Pacman included, child nodes will be equally-weighted, which means the return value can simply be the average of all child values. This assumption is not true in the case of directional ghosts but it suggests to us that expectimax might work better against random ghosts. For the rest, expectimax algorithm has the same structure as minimax but it is not possible to apply alpha-beta pruning since we don’t have the exact bounds on possible values (but we can still approximate them).
Minimax vs Expectimax
Before going on with the last agent, let’s take a break and compare the effectiveness of minimax and expectimax in a particular scenario.

As we can see from the above picture, we have that Mr.Pacman is trapped between two ghosts. Apparently, it has no chance to survive. But what if the ghosts take only random actions? Let’s start with the minimax agent and observe the result.

As expected, the minimax agent will decide that being eaten by the red ghost is the best move to maximize its score…And it’s actually right. In fact, it doesn’t know that the ghosts act randomly but knows that if the two ghosts move following their optimal policy they would have a chance to win the game.
Moreover, since for each step the score would be decreased by 1, minimax algorithm finds out that being eaten as soon as possible is the best move to increase its score, or better, to decrease it the least possible.
Now let’s play again in the same maze, but this time deploying an expectimax agent.
Magically, it manages to eat all dots in such a tricky maze. Anyway, as we remember how expectimax works we shouldn’t be so surprised. In fact, the algorithm assumes ghosts act randomly and in this case, it is exactly how the ghosts move.
Thus, when searching for its best possible move, it keeps into consideration the possibility of ghosts taking the wrong action, namely stepping away from Mr.Pacman. In this way, the blue ghost may open a way for the player to eat all the tree dots and win the game.
Deep Search Agent
The last agent we are going to see is still a depth search agent but unlike its predecessors, it doesn’t take into consideration the presence of ghosts. This way it can save the computation time ghosts need to simulate their moves and use it to further expand the search tree of its own moves.
This modification allows the agent to localize also more distant elements but the solution won’t be optimal since it doesn’t keep into consideration the fact that a ghost might be found in a certain position but moving to another position where it could obstruct the best path found by the algorithm in a future step.
Anyway, considering the best path is recomputed after each step, in practice, this agent behaves quite well in most of the mazes and is not influenced by the number of ghosts but only by the depth of its own search tree. Furthermore, it doesn’t evaluate only the goodness of the state found at the end of each branch, but the values of the explored states in the same branch are summed up to give a value to each branch and not just to the single leaves.
This trick allows the agent to take its decisions not only based on the final state but on what actually happens along the path to reach it. Its evaluation function is computed in a way similar, but not the same, to the evaluation function of the Reflex agent but values of deeper states are discounted to give more importance to nearer states, which are also more likely to occur (this concept is similar to the discount factor used to compute rewards in reinforcement learning algorithms).
Considering that this agent ignores ghosts during its search, high values of research depth are not very useful since ghosts can change their position while exploring more distant states. In practice, values between 2 and 6 have resulted in giving the best performances in most of the mazes.
We are going to call this last agent as DeepSearch Agent X where X is the maximum depth of its research tree. This algorithm has been re-proposed here since it already achieved very good results in the game of Snake.
Important: Video 1, Video 3, and Video 5 show a DeepSearch 6 agent playing in three different mazes.
Mazes overview
Now that we have finished describing all the agents, let’s have a look at the different mazes they have been tested, leaving their results in the last section.
The first maze is the medium maze, it is not too difficult or too hard and can successfully be completed by all the agents. Besides the two ghosts, the maze doesn’t present any particular obstacle and can also be easily won by a human player.

The second one is the open maze. The absence of walls inside the arena heavily slows down the multi-agent adversarial algorithms as well as the deep search one and in rare occasions, it might cause the Reflex agent to indefinitely loop around a dot pursued by the ghost preventing the game to be finished.
Nevertheless, given the structure of the maze, deep research trees are obsolete and elementary algorithms can often perform better than more complex ones.

Abandon all hope, ye who enter here.
Tricky maze welcome message
The third one is the feared tricky maze. We can consider it as a Pacman agents’ graveyard since no agents managed to complete it when directional ghosts were wandering around.
In fact, it has been designed to be particularly difficult for artificial intelligence to move through it and only deep search algorithms are able to perform quite well in it despite none of the ever managing to win.
Conversely, it is possible to win if ghosts are random, but still with a very low success rate.
The fourth and last maze is the original maze of the classic Pacman which is shown at the beginning of the post with the DeepSearch 6 agent completing it.
Agents comparison
In this last section, we are going to evaluate the performance of all the agents and compare them in four tables, one for each maze. Each agent has been made running for 100 games in all 4 mazes, one by one, two times: the first time with random ghosts and the second time with the more feared directional ghosts wandering around.
Important: Minimax agent uses the alpha-beta pruning variant and for both minimax and expectimax has been used a depth value of 2.
Important: There is a very low chance that Reflex agents can get stuck in the open maze with directional ghosts. In that case, there is nothing to do but close the program and run it again.
| agent | random ghost | directional ghost |
|---|---|---|
| Reflex | 1336 (0.74) | 351 (0.06) |
| Minimax | 371 (0.10) | 166 (0.03) |
| Expectimax | 426 (0.18) | 177 (0.04) |
| Deep Search 2 | 1336 (0.82) | 534 (0.18) |
| Deep Search 6 | 1468 (0.87) | 753 (0.35) |
“score (win ratio)” format
| agent | random ghost | directional ghost |
|---|---|---|
| Reflex | 972 (1) | 1218 (1) |
| Minimax | 728 (0.92) | 712 (0.54) |
| Expectimax | 749 (0.90) | 685 (0.57) |
| Deep Search 2 | 1239 (1) | 1233 (1) |
| Deep Search 6 | 1240 (1) | 1235 (1) |
“score (win ratio)” format
| agent | random ghost | directional ghost |
|---|---|---|
| Reflex | 708 (0.09) | 192 (0) |
| Minimax | 238 (0.01) | -60 (0) |
| Expectimax | 317 (0) | -61 (0) |
| Deep Search 2 | 713 (0) | 404 (0) |
| Deep Search 6 | 729 (0) | 492 (0) |
“score (win ratio)” format
| agent | random ghost | directional ghost |
|---|---|---|
| Reflex | 1319 (0.25) | 489 (0) |
| Minimax | 424 (0.) | 381 (0) |
| Expectimax | 403 (0) | 249 (0) |
| Deep Search 2 | 1477 (0.43) | 789 (0.01) |
| Deep Search 6 | 1654 (0.54) | 740 (0.01) |
“score (win ratio)” format
Due to hardware limitations, multi-agent adversarial algorithms have used a very limited search depth. Therefore, Minimax and Expectimax agents didn’t perform very well but their effectiveness has been proved in smaller-size mazes where even a very deep search range would result in a still manageable tree.
Overall, the DeepSearch 6 agent seems to achieve the best scores on most of the mazes making it the best-performing agent followed by DeepSearch 2 and Reflex.
Furthermore, it’s interesting observing how the Reflex and Minimax agents were the only two agents which managed to win in the tricky maze with random ghosts while the DeepSearch agents were the only ones to win the original maze with directional ghosts, that is, they won in the real Pacman game.
